This post is part of my sporadic Notes to a Young Software Engineer series. It was originally published on Hacker Noon in April 2019.

If you woke up one day resolved to be a great writer, you’d hear two simple pieces of feedback: write a lot, and read even more.1
In software, plenty of people write code, but precious few spend time reading it—especially code outside their day to day work. That is a mistake. Early in your career, act like an aspiring writer and embrace reading diverse code.
Read widely and read often. It could be the difference between being a decent software engineer and a great one.
Why should I read code?
Great writers are a function of the writers they’ve read. Think of Joan Didion, who typed out Hemingway’s sentences at 16, so she could learn how sentences work. Or think of Abraham Lincoln, whose later lyricism sprung from his beloved King James Bible.2
Similarly, seeing diverse coding practices lets you expand your palette when it comes time to write your own code. Reading others’ code exposes you to new language functionality and different coding styles.
Reading your dependencies will make you a more productive programmer. You’ll know the full functionality your dependencies offer. You’ll know exactly how they work and what tradeoffs they’re making. You’ll know where to debug when things go wrong.
Being comfortable reading code also reduces the likelihood that you’ll overly favor your code. The more you read, the more comfortable you’ll feel augmenting someone else’s code, rather than building your own. This change will reduce the likelihood you’ll be bitten by the “not invented here” syndrome.
Whether you are a web developer, data engineer, or cryptographer, cultivating regular reading will teach you tools and products different from your day-to-day work.
As a web frontend engineer, reading a small part of a raytracer’s codebase will expose you to a wholly different set of constraints. As a database engineer, reading high-abstraction web code can show you how your users think. For all engineers, you’ll find value in periodically reading languages outside the one you work with each day.
As Donald Knuth remarks, “[reading code] is really worth it for what it builds in your brain. The more you learn to read other people’s stuff, the more able you are to invent your own in the future …”
Here’s how to make your code reading as painless and productive as possible.
How should I “read” code?
Approaching a codebase like you would a typical book3—reading passively from start to end—is a recipe for failure (though, ironically, this is how computers read code themselves).
Reading from the start means ignoring important context and having no sense for the structure that is to come. Passive reading—where you don’t write tests or fix bugs—prevents you from truly internalizing the code.
I use a four-party strategy for approaching any complex code base (RSDW for short):
- (R)un: compile, run, and understand what the code is supposed to do.
- Examine (S)tructure: Learn high level structure and review key integration tests.
- (D)ives: Follow key flows and read important data structures.
- (W)rite tests: Write tests and prioritize simple features and bug fixes.
Unlike a book, nearly all my friends struggle to read code without a particular goal in mind. Before reading a new code base, make sure you have a goal for what you want to achieve. This will make the codebase seem more manageable and provide motivation when the journey inevitably gets hard.
The RSDW method is a starting point, but over time, you should customize it to what works for you. Some people swear by writing tests and fixing bugs, while others always like starting by reviewing the integration tests.
At first, though, start with the RSDW method.
Run
The first step in reading code isn’t to actually read code. It’s to use the software.
Read code only once you have an understanding for what functionality the software offers. During this stage, you should be able to make a summary of the code and have an understanding what the inputs and outputs are.
Using the software forces you to get it to run. That means tracking down dependencies and, in some languages, compiling the code. For libraries, it means calling a few of the popular functions. This is the time to run tests and review the output messages.
If you have trouble getting the system running on the first go, it’s the perfect time to document for others what it actually takes to run the software.
Structure
Next, identify the most critical parts of the code. This process is the part that is most different from reading a book. Instead of beginning at the beginning, you have to jump around to identify the key nexuses in the code.
Start with understanding the structure of the code. At minimum, run a few automated tools (such as tree and cloc) to figure out the languages and files of the codebase.
To identify the key files, look at the most modified files 4 and use any other advanced tools. Review the most important integration tests, listing out the functions that are called. Flag these tests for later.
There’s an easy way to short circuit this process too: find someone who’s worked on the code before. Understanding the structure is a good first task for a whiteboard session.
Deep Dives
Once you have a lay of the land, dig in.
When reading code, you should look at code flows (seeing the actions that are being created) and look at data structures/objects (where the results of actions are stored).
Pick three to five critical flows you’ve found from key integration tests, important PRs, or your review of the source files. Then dive deeper. Start at the top of a specific action and trace the code through. Some developers swear by debuggers that let you step through. Others prefer building Unified Modeling Language (UML) diagrams or flame graphs.
FlameGraph
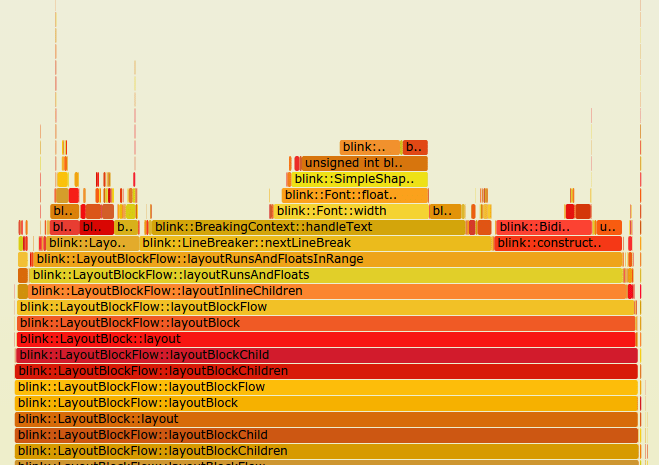
Source: FlameGraph Repository
Source: Wikimedia
{kind=link}

Other times, I’ll stop at a breakpoint smack dab in the middle of an important function, and work my way through the stack to understand how I got there. If you decide to manually follow the code, make sure your editor is setup to let you use “go to definition” and “find all references” for quick navigation.
For data structures, review the data types and when key variables are being set. Use the debugger to interrogate these data structures at critical moments.
In addition to integration tests, reviewing important pull requests are a powerful way to approach a new code base. PRs often are easier to understand, as they encapsulate an isolated feature. PRs also provide the narrative background beyond the why and how of a code addition.
During these deep dives, I keep two markdown docs open. The first is a “level up my coding” doc where I list out new syntax I’m seeing and code patterns I find interesting for my own learning (others call this a glossary). The second is a doc that lists out key questions I have for the developers of the codebase. At this stage, I also add to the documentation when I notice gaps.
Deep dives are especially powerful in pairs with someone who knows the code. If I have limited time with a developer on the project, I always have them trace me through a few key flows. Once I have a basic understanding of a few key flows, it’s much easier to dig in on my own.
Write Code
Unlike literature, where reading and writing are separate endeavors, a critical part of “reading” code is actually writing code. Without writing code, it’s nearly impossible to internalize a code base. The two easy approaches to start are to write tests and address simple features/bugs.
Writing tests is an active form of reading, forcing you to pay attention to the actual inputs and outputs of a particular interaction. Writing tests imprints the code in your memory in a way that reading alone cannot.
For me, unit tests are an easy way to start. Once I have some base mastery, I move over to integration tests that force me to understand increasingly larger parts of the codebase. Sometimes I’ll even rewrite an existing integration test, to test my understanding of how a critical call works.
The other easy approach is to write simple features or address easy bugs. Both of these tasks don’t demand complete knowledge of the codebase, but still force you to confront the code. Contributing bug fixes and documentation is also an easy way to give back to your dependencies.
These methods provide quick wins, when you need it most. By augmenting RSDW with a few broader lessons, reading code will become less daunting.
Some tips for reading
The RSDW process is not dogmatic. Inevitably, engineers figure out the personal ways they like to dig into a new code base (the process also varies dramatically based on language, the tooling available, and the type of code base in front of you).
Despite that, the RSDW process does argue for a systematic approach when you’re seeing new code. It also encourages active introspection into the code, be it writing tests or actively using a debugger to interrogate data structures. The process of reading code is far different than the more passive process of reading books.
You’ll also find reading new code is exhausting. You are intricately retracing code flows and trying to concurrently hold tens of new data structures and functions in your head. Be aggressive about taking breaks when you’re approaching a new code base. When I’m starting on a new codebase, a few good hours of a day of reading is all I need to feel productive.
While it’s critical to develop good reading skills, it’s just as important to be thoughtful about what you read.
What code should you read?
Early in your career, I believe that 60% of your time should be spent reading code. Maybe half of that should be code outside of the direct codebases you actually build on. That’s an awfully large amount of time to fill, so what should you read?
The easiest way to get started reading, and the highest ROI, is to learn your dependencies. Internalizing how your dependencies work lets you more easily debug and reason across your entire system.
The other high ROI path is to pick an important system at your company that you interface with, and read through it. Not only will this be valuable in your work, but professional codebases are different from open source codebases. They are written closest to how your team’s engineers feel is the “right” way.
Beyond the direct systems you interact with, cultivate an openness to reading widely. Early on, I recommend putting aside an hour in the morning or evening to read through code outside your day to day work. It sounds painful after a hard day of work, but pick a codebase you’re excited to dig into and try it for a week.
For example, Redis is known as a popular starting point in C. For less readable, more complex codebases an easy way to start is to read a specific subsystem.
Side projects are a powerful way to read, because they force you to learn a different world. You’ll need to read new dependencies and explore different codebases for what you’re building. Though it doesn’t seem like reading, it’s a project that forces you to actively read what you’ll be using.
Outside work, you should read tools widely different from your day job. If you’re used to high level abstractions, learn an abstraction level (or three) down. If you work in one language, pick another language to read in your free time. If you consistently have to think about one constraint (e.g., the time for next screen refresh in graphics programming), find another constraint (e.g., saving battery life in mobile programming).
Another good approach to reading code is to read and rewrite coders you respect. Where a young Didion wrote Hemingway or Hunter Thompson typed out the Great Gatsby, write out antirez’s or gaearon’s or mrdoob’s code starting with a simple library. Read their other codebases. Stay up to date of their most recent work.
Stephen King cautioned writers that “if you don’t have time to read, you don’t have the time (or the tools) to write. Simple as that.” Similarly, for software engineers, writing fresh code may be the most fun, but (actively) reading code is what will separate you from the pack.
Links
Articles on reading code
- Ask HN: How do you familiarize yourself with a new codebase
- Ask HN: How to understand the large codebase of an open-source project?
- Strategies to quickly become productive in an unfamiliar codebase
- What’s the best way to become familiar with a large codebase?
- Tips for Reading Code
- Software Engineering Radio: Software Archaeology with Dave Thomas (Podcast)
Books
Codebases to read
You can read more of my Notes to a Young Software Engineer series. feedback or ideas for other posts? drop a note to nemil at this domain
Thanks to Brandur Leach, Jake Craige, and Breck Stodghill for reflections and feedback.
- Steve Zissner makes this point in his famed, On Writing Well, as does Stephen King in On Writing. ↩
- Lincoln biographer William E. Barton wrote that Mr. Lincoln “read the Bible, honored it, quoted it freely, and it became so much a part of him as visibly and permanently to give shape to his literary style and to his habits of thought. (link) ↩
- An atypical book might be an encyclopedia, where it seems daft to read straight through. ↩
- Hat tip to macromaniac:
git log --pretty=format: --name-only | sort | uniq -c | sort -rg | head -10↩